聽說GPT很強,為什麼別人用起來感覺比較好?
AI為什麼總是出錯 ? 又該怎麼強化AI能力 ? 先知道AI如何理解語言,我們就可以更深入的提高AI的使用能力!
AI出現幻覺 ?!
我們常覺得 AI「很笨」的時候,往往是因為它看不懂我們的提問、亂答問題、甚至編造不存在的內容。這類情況在技術上被稱為「AI 幻覺」(AI Hallucination)──意思是模型生成了看起來合理,實際卻錯誤或虛構的內容。
要理解 AI 為什麼會產生幻覺,我們得回到它的核心運作機制──演算法,尤其是它所依賴的架構:Transformer(轉換器)。
Transformer 的運作邏輯是:
它會根據你提供的文字,判斷哪些詞語重要,給予較高的權重,然後依據這些關係逐字預測下一個最可能出現的詞,一步步產生回答。
這代表它不是「查資料」或「理解真相」,而是「根據模式預測最接近的詞彙」。
所以如果你問的方式不清楚、資訊不完整,或它過去學到的資料本身有偏差,它就可能預測錯方向,甚至「一本正經地胡說八道」。
AI「理解」語言的實際過程
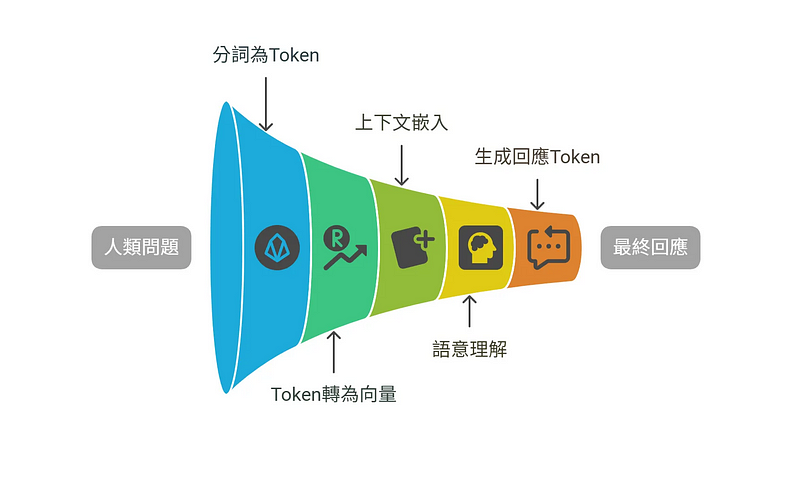
以下是AI理解人類語言的大致過程:
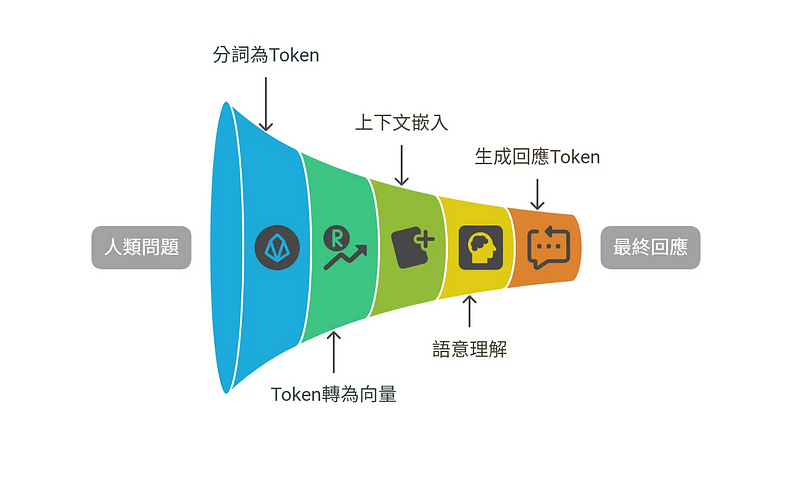
- 把人類詢問的問題文字,先分詞變成文字單位「Token」
「你好嗎」 → ["你", "好", "嗎"](也就是變成3個Token)2. 把「Token」變成模型內部的「Token 向量」,也就是可以讀取(理解)的最小單位,這個過程稱為 Token embedding。
"你" → [0.12, -0.88, ..., 0.01]
"好" → [0.65, 0.12, ..., -0.34]
"嗎" → [-0.22, 0.31, ..., 0.91]3. 接下來透過 Transformer 結構的多層編碼器,模型會考量整段文字的上下文,逐步運算並更新每一個 token 的向量。這個過程產生的就是 Contextual Embedding —— 每個 token 的最終語意向量,已包含整體語境的理解。
這裡同步做了兩件事「上下文」+「語意理解」,實際上就是在把更多向量資訊納入後,重新調整向量,這個過程被我們當成「AI在了解人類的意思」。
"你" → [0.12, -0.88, ..., 0.01]
"好" → [0.65, 0.12, ..., -0.34]
"嗎" → [-0.22, 0.31, ..., 0.91]
--
在 "你好嗎" 的上一句問題是"全部的語言模型中誰最好?" ,同步參考上一句的
向量後,對你好嗎形成新的向量。
-----
"你" → [0.65, 0.12, ..., -0.14]
"好" → [0.65, 0.12, ..., -0.54]
"嗎" → [0.12, -0.88, ..., 0.01]4. 生成回應的Token向量,逐字預測提供回傳(文字接龍)
AI 回答「我覺得我最強!」這句話,其實是這樣來的:
我(最有機會)
我覺(也合理)
我覺得(接下來)
我覺得我最強!(完成)
---
而且每生成一個字,AI都會參考包含GPT自己生成的內容
(原本內容) + 我 => 我覺
(原本內容) + 我覺 => 我覺得
--
就像一個人在打字的感覺,只是模型產出的是向量、數字,才再轉換成文字
[0.12, -0.88, ..., 0.01] → "我"
[0.65, 0.12, ..., -0.34] → "覺"
[-0.22, 0.31, ..., 0.91] → "得"
[0.12, -0.88, ..., 0.01] → "我"
[0.65, 0.12, ..., -0.34] → "最"
[-0.22, 0.31, ..., 0.91] → "強"所以,AI提供給你資料的過程是這樣的:
1. 轉成Token
「你好嗎」 → ["你", "好", "嗎"]
2. 轉為向量
"你" → [0.12, -0.88, ..., 0.01]
"好" → [0.65, 0.12, ..., -0.34]
"嗎" → [-0.22, 0.31, ..., 0.91]
3. 加入上下文後,進行模型轉換,重新產出新向量
加入"全部的語言模型中誰最好?" 後產生
"你" → [0.65, 0.12, ..., -0.14]
"好" → [0.65, 0.12, ..., -0.54]
"嗎" → [0.12, -0.88, ..., 0.01]
4. 持續產出轉換結果
[0.12, -0.88, ..., 0.01] → "我"
[0.65, 0.12, ..., -0.34] → "覺"
[-0.22, 0.31, ..., 0.91] → "得"
[0.12, -0.88, ..., 0.01] → "我"
[0.65, 0.12, ..., -0.34] → "最"
[-0.22, 0.31, ..., 0.91] → "強"了解了細節過程,就可以更好的回答「為什麼會產生AI幻覺 」
- 上下文拆得不對:
當模型把「你好嗎」拆成:
「你」「好嗎」
「你好」「嗎」
因為拆解成不同結構,那在之後的預測階段就更可能錯。 - 轉換預測錯誤:
例如模型預測階段:
我 ⇒ 我覺得 ⇒ 我覺得心情 ⇒ 我覺得心情好
一旦某個詞預測錯了(例如預測成「心情」而不是「我」),接下來的預測就會基於錯誤的詞繼續往下生成,錯誤會一路延續,形成「將錯就錯」的現象。 - 上下文加入的時候,加入了奇怪的內容
模型可能誤以為「牛肉麵」和「台積電」是同一主題下的相關資訊,導致語意判斷錯誤。
因此,希望他回答得好,就有幾種方向:
- 打字要打完整,並用常使用的語句,不然容易預測錯誤(拆字拆錯)
- 重新輸入一次,讓它重新生成(因為 Transformer 是基於機率進行預測,每次會從機率較高的幾個選項中挑一個,並不是固定答案)
- 訓練它的文字轉向量的轉換能力(但可能大部分人不具備)
- 提供更清楚的上下文和完整語意,能幫助模型更準確地掌握我們的意圖
接下來,讓我們來看看關於上下文,還有什麼樣的細節可以讓我們強化AI
<完整內容,請參考數位商品>

給非工程師的 AI 知識導讀
從 ChatGPT 到 AI Agent,一口氣補上 2025 該懂的核心概念!
15,000 精實內容,沒有 10 個熱門工具、不會有一堆實戰技巧,而是從 ChatGPT 開始,用故事、圖表、案例。
讓非工程師的你,也能把 AI 名詞、基本觀念一次串起來!