Chat-GPT 是什麼 ?
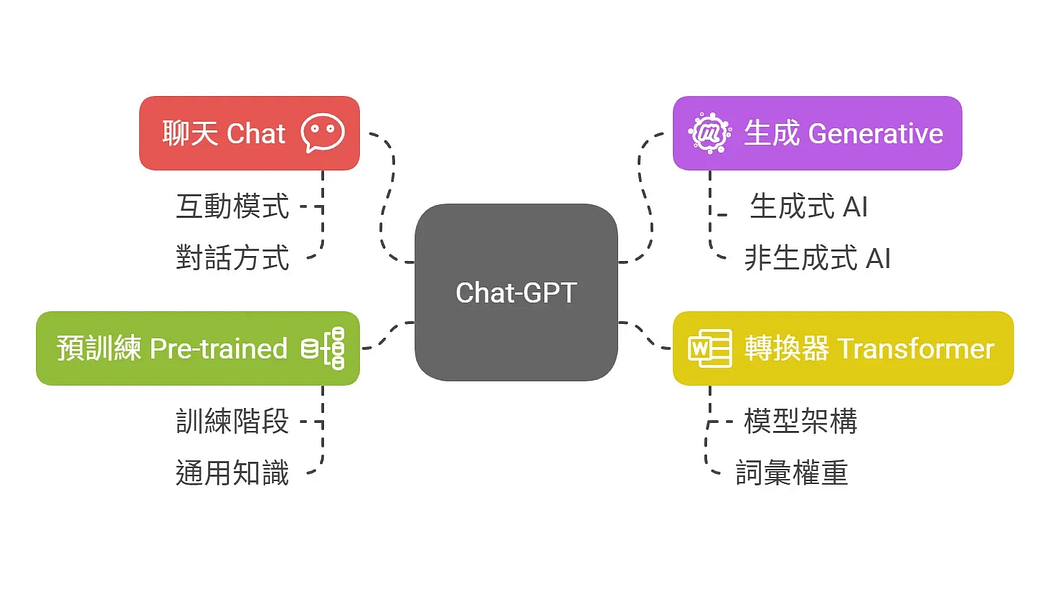
ChatGPT,全稱「聊天生成預訓練轉換器」(Chat Generative Pre-trained Transformer),程式運作主要基於GPT-3.5、GPT-4、GPT-4o、GPT-4.5..等的大型語言模型(LLM)。
光是這些簡寫,就有多個名詞,我們分別來解釋一下。
聊天 Chat
指的是它的互動運作模式是用聊天的方式,所以你可以打開視窗,就像在跟他對話一樣的方式輸入文字來互動。
生成 Generative
指的是能夠產生文字、圖像或其他媒體以回應,所以我們會聽到所謂「生成式AI-Generative AI」就是在講這個。
既然有生成式,就也有非生成式的AI,但大多會被稱為「分辨式 AI」,「分辨式 AI」的重點在於進行「判斷、分類」,例如:病人有沒有的癌症的「Yes / No」的回答、了解你喜歡聽流行歌、古典樂..等進行分類標籤。
預訓練 Pre-trained
指的是訓練階段,事先進行訓練,整個訓練完畢之後才給你使用。通常預訓練階段,運用大量數據資料進行訓練,讓他學習到通用、普遍性的知識。
既然有預先訓練,當然也有模型完成後再訓練,這個我們會在後面講到。
轉換器 Transformer
是一種模型架構,特色是能幫 AI 分析文字中每個詞的重要性,並為它們分配不同的權重。
白話來說:你給它一段文字,它會判斷哪些詞對理解最關鍵,給它們較高權重,然後根據這些判斷來生成回應。
而他之所以被稱為大型語言模型(large language model,LLM),我們可以再來說文解字一下。
- 大型:是因為它經過了大量資料的訓練,內部包含了上千億個參數,這些參數就像是它學會如何理解、預測語言的「經驗」。所以模型能夠回答各種主題,靠的就是這些龐大的內部結構與資料量。
- 語言:指的是它主要處理的資料類型是自然語言,也就是像中文、英文這種我們平常使用的文字(不是圖像、聲音或音樂)。
- 模型:則是一個被訓練過的「輸入→輸出」系統。你給它一段文字,它會根據訓練時學到的規律,預測接下來最可能出現的文字。
所以ChatGPT 是:
基於
- 「大型」(Large)
- 「語言」(Language)
- 「模型」(Model)
所構建的系統,結合了
- 「聊天」(Chat)
- 「生成」(Generative)
- 「預訓練」(Pre-trained)
- 「轉換器」(Transformer)
等技術。
用剛剛的概念來說,它是這樣一個系統:
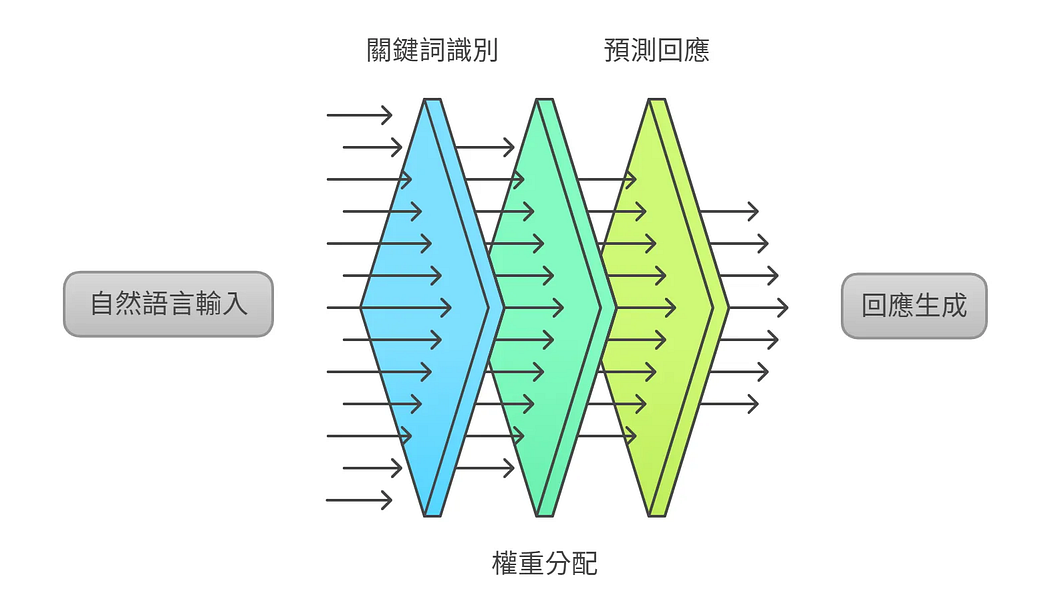
你輸入自然語言,它用聊天互動的方式,產出回應。 這些內容不是即時查資料,而是透過過去看過的大量資料,經由訓練過的模型, 再根據輸入內容中的關鍵詞分配不同的權重,來生成它預測最適合的回應。
之所以被稱為人工智慧(Artificial Intelligence),是因為它是由人設計、電腦執行,卻能產出類似人類思考與理解的行為,因此具備某種程度上的「智慧感」。
它的「智慧」來源,就是透過 Transformer 架構,分析你提供的文字,判斷哪些訊息比較重要、該給哪些詞更高的權重,進而產生合理的內容回應。
當然,大型語言模型(LLM)並不只有 OpenAI 提供的 GPT 系列(如 GPT-3.5、GPT-4),目前市面上還有多種不同機構推出的模型,例如:
- Claude(由 Anthropic 開發)
- Grok(由 Elon Musk 創立的 xAI 團隊開發)
- Gemini(由 Google DeepMind 開發)
- LLaMA(由 Meta 開發)
這些模型的核心設計大多也基於 Transformer 架構,但在訓練資料、能力特化、授權方式上各有差異。